
Daten sind entscheidend für die Entwicklung von Anwendungen der künstlichen Intelligenz (KI). Die schnelle Verfügbarkeit von Daten ist jedoch aufgrund immer strengerer Datenschutzbestimmungen eine Herausforderung.
Eine mögliche Lösung ist die Verwendung synthetischer Daten. Gartner prognostiziert, dass bis 2024 60 % der Daten, die zur Entwicklung von KI- und Analyseanwendungen verwendet werden, synthetisch generiert werden.
Was genau sind KI-generierte synthetische Daten?
Wo Originaldaten durch Interaktionen mit Einzelpersonen gesammelt werden, werden synthetische Daten von einem KI-Algorithmus generiert, der völlig neue und künstliche Datenpunkte generiert. Es ist neu, KI im Datensyntheseprozess anzuwenden, um die generierten synthetischen Daten so zu modellieren, dass sie die Eigenschaften, Beziehungen und statistischen Muster aus dem ursprünglichen Datensatz nachahmen. Das nennen wir einen synthetischen Datenzwilling, bei dem man originale sensible Daten mit einem KI-Algorithmus nachahmt.
Synthetische Daten in der Praxis
Syntho, ein Experte für KI-generierte synthetische Daten, will mit KI-generierten synthetischen Daten Privacy by Design in einen Wettbewerbsvorteil verwandeln. Sie helfen Unternehmen beim Aufbau einer starken Datengrundlage mit einfachem und schnellem Zugriff auf hochwertige Daten und haben kürzlich den Philips Innovation Award gewonnen.
Die Generierung synthetischer Daten mit KI ist jedoch eine relativ neue Lösung, die in der Regel häufig gestellte Fragen aufwirft. Um diese zu beantworten, hat Syntho zusammen mit SAS eine Fallstudie gestartet. In Zusammenarbeit mit der Dutch AI Coalition (NL AIC) untersuchten sie den Wert synthetischer Daten, indem sie KI-generierte synthetische Daten, die von der Syntho Engine generiert wurden, mit Originaldaten über verschiedene Bewertungen zu Datenqualität, Rechtsgültigkeit und Nutzbarkeit verglichen.
Ist Datenanonymisierung keine Lösung?
Klassische Anonymisierungsverfahren haben gemeinsam, dass sie Originaldaten manipulieren, um die Rückverfolgung von Personen zu erschweren. Beispiele sind Generalisierung, Unterdrückung, Löschen, Pseudonymisierung, Datenmaskierung und Mischen von Zeilen und Spalten. Beispiele finden Sie in der folgenden Tabelle.

KI-generierte synthetische Daten und fortschrittliche Analysen
Die synthetische Datengenerierung mit KI bewahrt grundlegende Muster, Geschäftslogik, Beziehungen und Statistiken (wie im Beispiel unten). Die Verwendung synthetischer Daten für grundlegende Analysen führt somit zu zuverlässigen Ergebnissen. Synthetische Daten enthalten nicht nur grundlegende Muster (wie in den vorherigen Diagrammen gezeigt), sondern erfassen auch tief „versteckte“ statistische Muster, die für erweiterte Analyseaufgaben erforderlich sind. Letzteres wird im Balkendiagramm unten gezeigt, was darauf hinweist, dass die Genauigkeit von Modellen, die mit synthetischen Daten trainiert wurden, im Vergleich zu Modellen, die mit Originaldaten trainiert wurden, ähnlich ist. Darüber hinaus schneiden die mit anonymisierten Daten trainierten Modelle mit einer Fläche unter der Kurve (AUC*) von fast 0,5 bei weitem am schlechtesten ab. Der vollständige Bericht mit allen Advanced-Analytics-Bewertungen zu synthetischen Daten im Vergleich zu den Originaldaten ist auf Anfrage erhältlich.
*AUC: Die Fläche unter der Kurve ist ein Maß für die Genauigkeit von Advanced-Analytics-Modellen unter Berücksichtigung von Richtig-Positiven, Falsch-Positiven, Falsch-Negativen und Richtig-Negativen. 0,5 bedeutet, dass ein Modell zufällig vorhersagt und keine Vorhersagekraft hat, und 1 bedeutet, dass das Modell immer richtig ist und volle Vorhersagekraft hat.
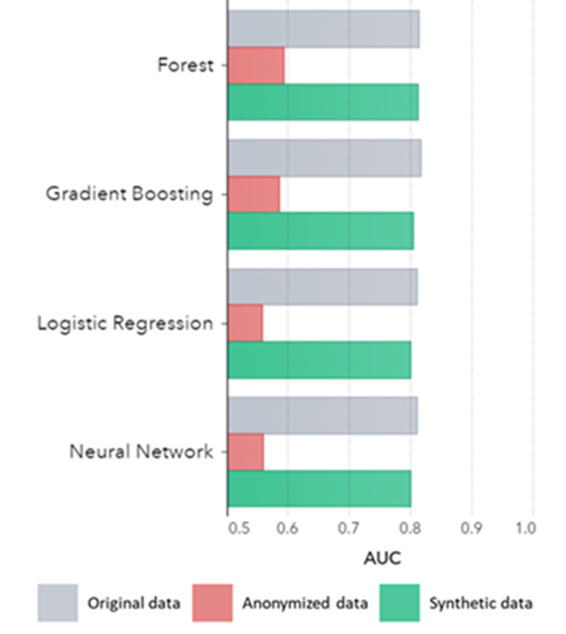
AUC nach Algorithmus gruppiert nach Methode
AUC nach Algorithmus gruppiert nach Methode
Darüber hinaus können diese synthetischen Daten verwendet werden, um Dateneigenschaften und Hauptvariablen zu verstehen, die für das eigentliche Training der Modelle benötigt werden. Die von den Algorithmen ausgewählten Eingaben für synthetische Daten im Vergleich zu Originaldaten waren sehr ähnlich. Daher kann der Modellierungsprozess auf dieser synthetischen Version durchgeführt werden, wodurch das Risiko von Datenschutzverletzungen verringert wird. Beim Rückschluss auf einzelne Datensätze (z. B. TK-Kunde) empfiehlt sich jedoch ein Nachtrainieren auf Originaldaten zur Erklärbarkeit, erhöhten Akzeptanz oder auch nur aus regulatorischen Gründen.
Weitere Schlussfolgerungen:
- Modelle, die mit synthetischen Daten trainiert wurden, zeigen im Vergleich zu den Modellen, die mit Originaldaten trainiert wurden, eine sehr ähnliche Leistung.
- Modelle, die auf anonymisierten Daten mit „klassischen Anonymisierungstechniken“ trainiert wurden, zeigen eine schlechtere Leistung im Vergleich zu Modellen, die auf den Originaldaten oder synthetischen Daten trainiert wurden.
- Die Generierung synthetischer Daten ist einfach und schnell, da die Technik pro Datensatz und Datentyp genau gleich funktioniert.
Synthetische Daten für die Modellentwicklung und erweiterte Analytik
Eine starke Datengrundlage mit einfachem und schnellem Zugriff auf nutzbare, qualitativ hochwertige Daten ist für die Entwicklung von Modellen (z. B. Dashboards [BI] und Advanced Analytics [AI & ML]) unerlässlich. Viele Organisationen leiden jedoch unter einer suboptimalen Datengrundlage, was zu 3 zentralen Herausforderungen führt:
- Der Zugriff auf Daten dauert aufgrund von (Datenschutz-)Vorschriften, internen Prozessen oder Datensilos ewig.
- Klassische Anonymisierungstechniken zerstören Daten, wodurch die Daten nicht mehr für Analysen und Advanced Analytics geeignet sind (Garbage In = Garbage Out).
- Vorhandene Lösungen sind nicht skalierbar, da sie je nach Datensatz und Datentyp unterschiedlich funktionieren und große Datenbanken mit mehreren Tabellen nicht verarbeiten können.
Synthetischer Datenansatz: Entwickeln Sie Modelle mit so gut wie realen synthetischen Daten, um:
- Minimieren Sie die Verwendung von Originaldaten, ohne Ihre Entwickler zu behindern.
- Entsperren Sie persönliche Daten und haben Sie Zugriff auf mehr Daten, als zuvor (z. B. aus Datenschutzgründen) eingeschränkt waren.
- Einfacher und schneller Datenzugriff auf relevante Daten.
- Skalierbare Lösung, die für jeden Datensatz, Datentyp und für riesige Datenbanken gleich funktioniert.
Auf diese Weise können Unternehmen eine starke Datengrundlage mit einfachem und schnellem Zugriff auf nutzbare, qualitativ hochwertige Daten aufbauen, um Daten freizusetzen und Datenchancen zu nutzen.Testen und Entwickeln mit qualitativ hochwertigen Testdaten sind für die Bereitstellung modernster Softwarelösungen unerlässlich. Die Verwendung originaler Produktionsdaten erscheint naheliegend, ist aber aufgrund von (Datenschutz-)Bestimmungen nicht erlaubt. Alternative Test Data Management (TDM) Tools führen "Legacy-by-Design" ein, um die Testdaten richtig zu machen:
- Reflektiert keine Produktionsdaten und Geschäftslogik und referenzielle Integrität werden nicht beibehalten.
- Die Arbeit ist langsam und zeitaufwändig.
- Handarbeit ist erforderlich.
Synthetischer Datenansatz: Testen und entwickeln Sie mit KI-generierten synthetischen Testdaten, um hochmoderne Softwarelösungen bereitzustellen, die intelligent sind mit:
- Produktionsähnliche Daten mit erhaltener Geschäftslogik und referenzieller Integrität.
- Einfache und schnelle Datengenerierung mit modernster KI.
- Datenschutz durch Design.
- Einfach, schnell und agil.
Auf diese Weise können Unternehmen mit Testdaten der nächsten Stufe testen und entwickeln, um hochmoderne Softwarelösungen bereitzustellen!



